We introduce HAMLET, a history-aware fine-tuning framework for Vision-Language-Action (VLA) models that augments pre-trained policies with temporal memory while preserving their existing competencies. HAMLET summarizes instantaneous vision-language representations at each timestep into moment tokens and consolidates them through a lightweight memory module to form a temporally informed condition for action prediction. This design delivers strong gains on long-horizon, history-dependent manipulation tasks without retraining from scratch.
HAMLET is a fine-tuning framework for VLAs that introduces History-Aware Memory with LEarned Tokens.
The framework has two components: (a) moment tokens, which summarize instantaneous VLM representations at each timestep, and (b) a memory module that aggregates moment tokens across timesteps to provide a temporally informed context for action prediction.
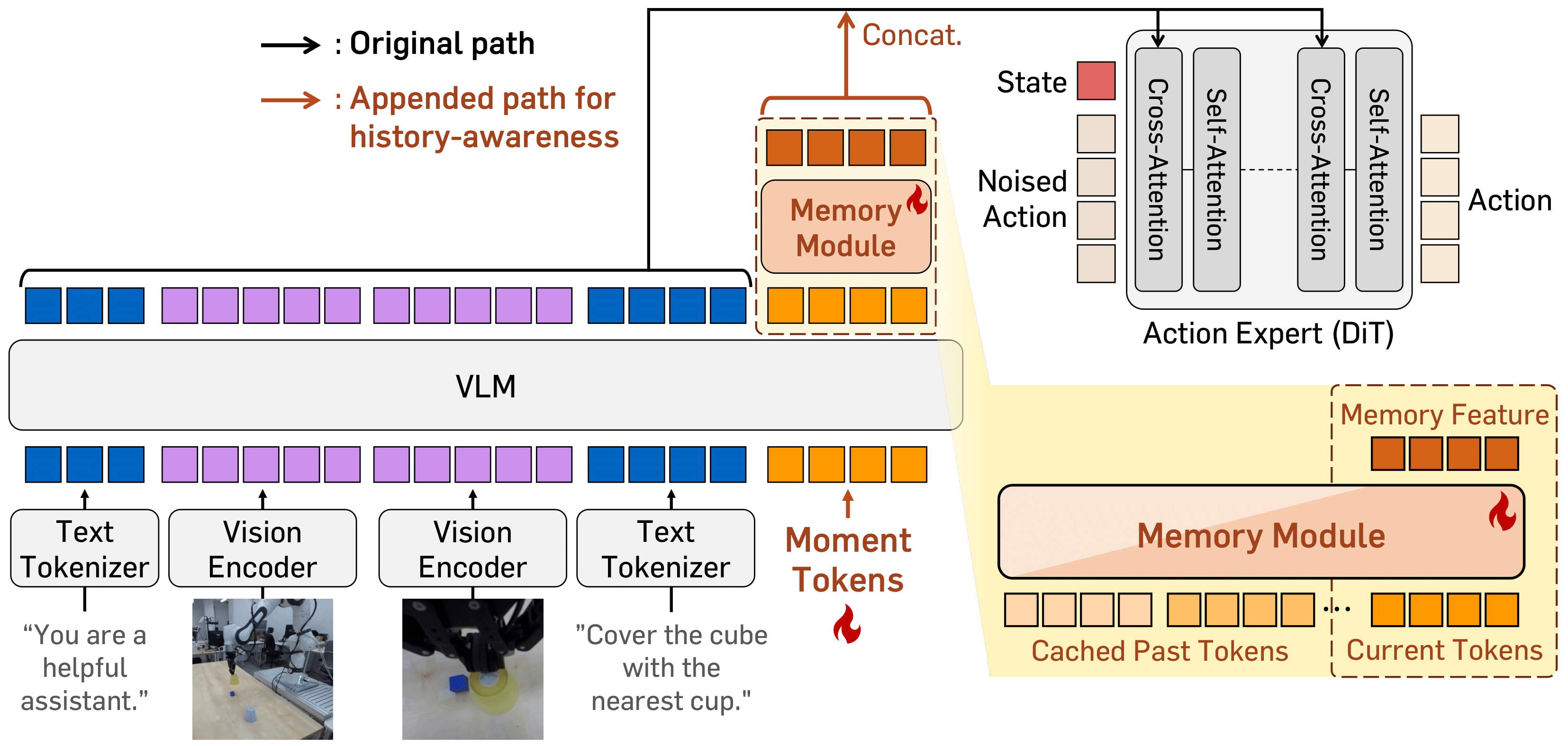
The moment tokens are appended to the VLM input at each timestep and initialized with time-contrastive learning, which encourages distinctiveness across timesteps. Building on this, we incorporate a lightweight memory module that stores and integrates moment token representations across timesteps.
We present several real-robot demonstrations for each real-world task.
Instruction "Pick up the cube and place it on the opposite side, and then return it to the original side."
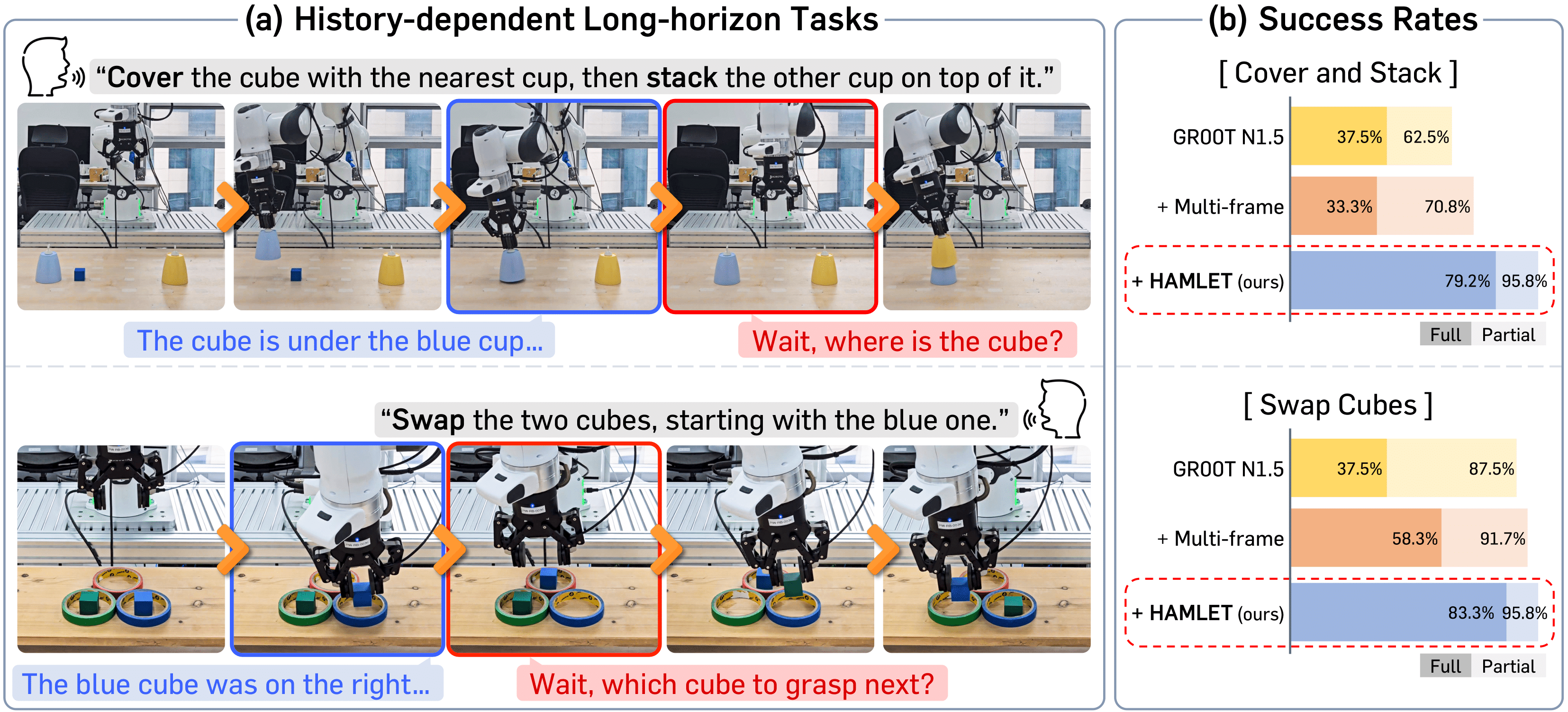
Instruction "Cover the cube with the nearest cup, then stack the other cup on top of it."
Instruction "Swap the positions of two cubes, starting with the blue one."